
GPT-Image-2 体验手记:它不只是更会画,而是开始“理解再表达”
我一开始其实没对 GPT-Image-2 抱太高预期。
毕竟这两年图像模型的升级,大多数都是:更清晰一点、更真实一点、更稳定一点。
但这次不太一样。
用了一段时间之后,我越来越觉得——这不是“画图模型升级”,而是把 GPT 那一套理解能力,真正搬进了图像生成里。
它最大的变化:开始“听得懂人话了”
以前用图像模型,你是要迁就它的。
你得学会怎么写 prompt,怎么堆关键词,甚至要试错很多次。
现在明显反过来了。
你可以像跟人说话一样描述需求,它居然真的能理解。
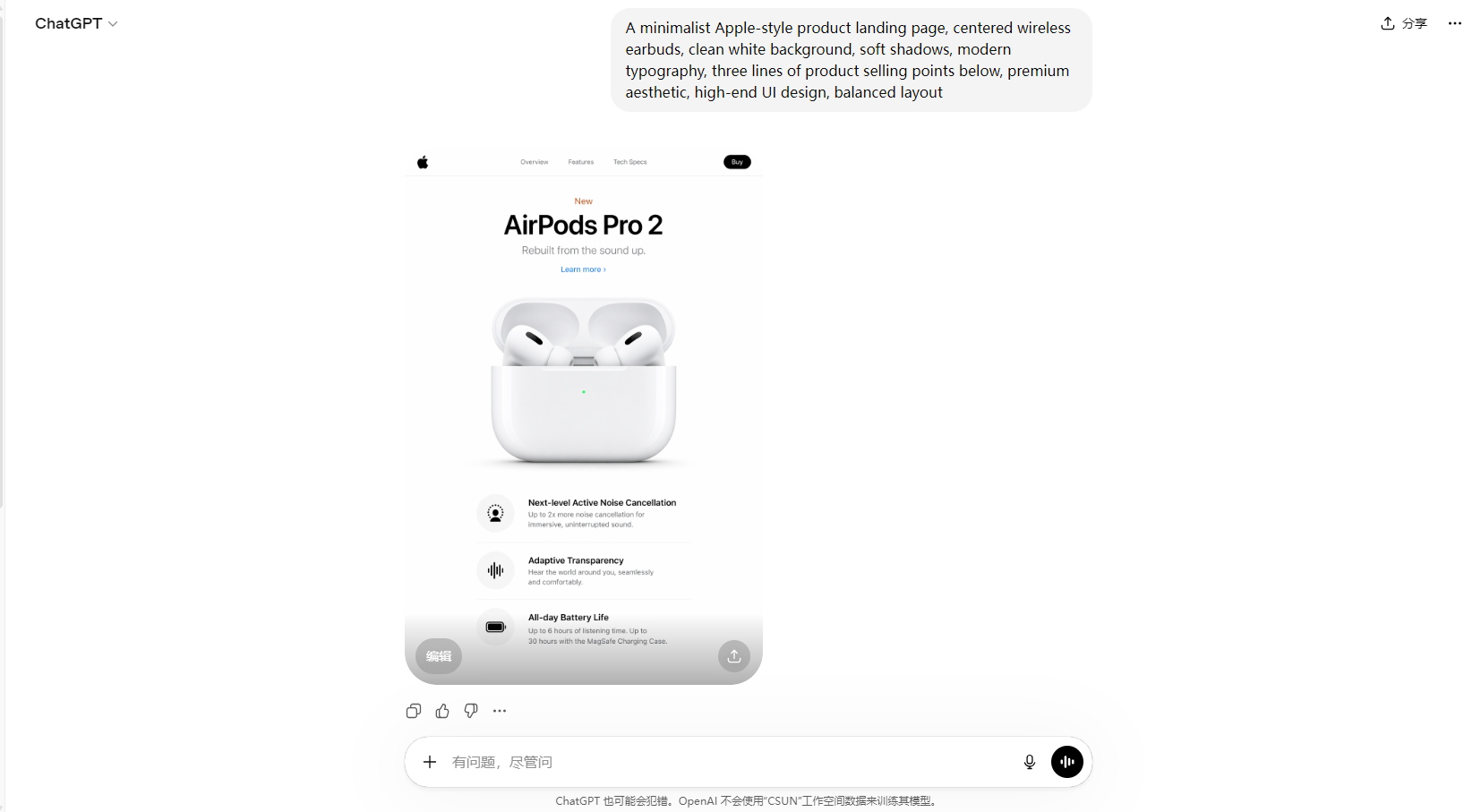
比如我试过这样一个需求:
做一个类似苹果官网的耳机产品页,中间是产品,下面有三行卖点,整体干净克制
它给我的结果是:
页面是有结构的(不是一张海报)
产品是居中的
文案真的分成三行
留白和风格都接近苹果官网
这在以前,基本不可能一步做到。
文字能力:第一次真的“能用了”
这是我最惊讶的一点。
过去所有模型都有一个硬伤:文字不行。
但 GPT-Image-2 已经到了一个很关键的节点:
👉 可以不用再专门修字了
我测了几个场景:
海报标题 → 基本稳定
UI界面 → 文案可读
英文 → 几乎没问题
中文 → 大多数情况可用
当然还不是100%完美,但已经是可以进入实际工作流的水平。


写实能力:开始有点“危险”的真实
这一代的真实感,说实话让我有点不太舒服。
因为它已经不只是“像”,而是可信。
我试过生成:
聊天截图
新闻页面
产品实拍图
结果是:很多情况下已经很难一眼分辨真假。
它厉害的地方不只是细节,而是“合理”:
光线是对的
噪点像真实相机
材质有物理逻辑
这和过去那种“AI感很强的精致图”完全不是一个层级。

一致性:终于能做“系列内容”了
以前最大的问题是:
👉 你可以生成一张图,但很难生成一套东西
比如角色一换角度就变脸,UI一换页面就变风格。
GPT-Image-2 明显改善了这一点。
我试过做一组插画,人物基本能保持一致;做产品图,风格也不会飘太多。
虽然还不是完全锁死一致,但已经能用来做:
漫画分镜
产品系列图
品牌视觉统一内容
这其实是一个很关键的分水岭。

它不像传统模型的地方:会“先想一下”
这个体验很微妙,但你多用几次会发现。
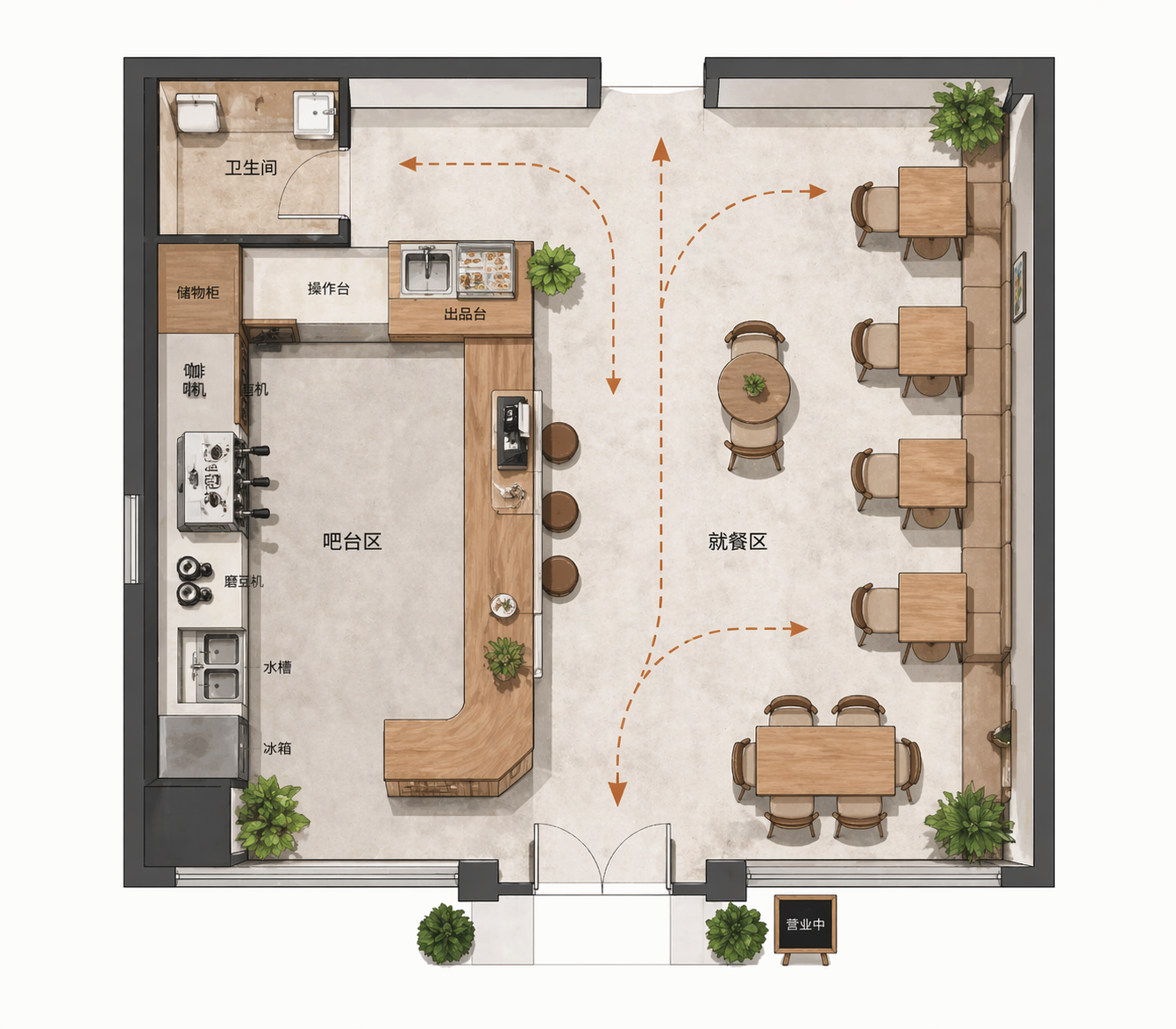
比如我让它画:
一个小型咖啡店的平面布局,要合理,有动线
以前模型是“拼一个看起来像的”。
现在它更像是:
👉 先理解空间,再画出来
结果是:
动线是通的
桌椅位置合理
功能区清晰
这已经有点“设计辅助工具”的味道了。
和 Midjourney 的真实差别
用一句很直白的话说:
Midjourney: 更像艺术家
GPT-Image-2: 更像设计师
Midjourney:
审美更强
风格更惊艳
但不太听话
GPT-Image-2:
理解能力强
可控性高
更适合做“有明确需求的图”
所以现在很明显:
👉 做艺术 → Midjourney
👉 做产品/UI/商业图 → GPT-Image-2
它真正改变的,是工作方式
以前流程是:
想法 → 草图 → 设计 → 修改 → 出图
现在变成:
想法 → 描述 → 调整几轮 → 成品
而且这个“描述”,不需要很专业。
这带来的变化其实挺大的:
设计前期被压缩
非设计人员也能做视觉输出
重点从“操作工具”变成“表达想法”
也说点问题(实际使用感受)
用下来还是有一些明显短板:
中文偶尔翻车
极复杂结构会错
某些艺术风格不如 Midjourney
生成速度略慢
这些问题不致命,但确实存在。
最后的判断
如果一定要给它一个定位,我会这样说:
它不是一个更强的画图工具,而是一个开始具备“理解能力”的视觉系统。
这件事的影响,可能比画得更好更重要。
因为从这一代开始,图像生成不再只是“创作”,而是:
👉 一种可以被指挥、被控制、被纳入工作流的能力

.jpg)